

Evaluation metrics that examine language quality, LLM task-specific criteria for evaluating certain tasks, and human evaluations are the three broad categories of evaluations that can gauge an LLM’s performance and accuracy.
Assessing LLMs is a difficult and multidimensional process that requires both quantitative and qualitative methods. Comprehensive evaluation techniques that address several facets of model performance and impact must be used when assessing LLMs. The absence of standardized assessments is one of the biggest problems we have, as it makes it very hard to compare various models in a methodical way in terms of their capabilities, possible dangers, and potential damages. This highlights the difficulty and significance of the review process because it means we lack an objective way to gauge how intelligent or good any of these particular models are.
When we talk about GenAI evaluations, most of the conversations focus on accuracy and performance evaluations, which measure how effectively a language model can understand and generate text that is similar to human language. Applications like chatbots, content creation, and summarisation jobs that depend on the caliber and applicability of the content they produce should pay close attention to this factor.
Traditional evaluation metrics that examine language quality, LLM task-specific criteria for evaluating certain tasks, and human evaluations are the three broad categories of evaluations that can gauge performance and accuracy.
LLM evaluation pillars: The foregoing should be the five critical design considerations when putting together an LLM evaluation framework that ensures that a systematic and rigorous approach and infrastructure are put in place for continuous model improvements.
Use Case Specificity: Testing the LLM on the use cases for which it was created—that is, applying the model to a range of natural language processing (NLP) activities, including translation, question-answering, and summarization—is necessary to provide a meaningful evaluation. Standard metrics, like ROUGE (Recall-Oriented Understudy for Gisting Evaluation), should be used in the evaluation process for summarisation in order to preserve comparability and dependability.
Prompt Engineering: The development of prompts is a crucial component of LLM evaluation. In order to provide a reliable evaluation of the model’s capabilities, prompts need to be clear and equitable. By doing this, the evaluation results are guaranteed to accurately represent the model’s performance.
Benchmarking: A critical technique that makes it possible to assess an LLM’s performance using pre-existing standards and alternative models is benchmarking. This not only monitors advancement but also pinpoints areas in need of development. Periodically assessing and improving the LLM is made possible by a continual review approach in conjunction with ongoing development procedures.
GenAI Ethics: At every stage of the LLM evaluation process, ethical considerations must be taken into account. Checking the model for biases, fairness, and ethical issues requires examining both the training data and the results. To make sure that the model’s outputs meet user needs and expectations, the evaluation should also include a significant section on the user experience.
Logging and monitoring: All aspects of the evaluation must be open and transparent. Maintaining a record of the criteria, procedures, and outcomes promotes confidence in the LLM’s skills and permits independent verification. The model, training data, and evaluation procedure should all be improved based on performance metrics and feedback, and the evaluation results should guide a cycle of continuous development.
See also: Navigating the AI Landscape: Why Multiple LLMs Are Your Best Bet
Evaluation scope: Model vs System
An LLM system is the entire setup that includes not only the LLM itself but also extra components like function tool calling (for agents), retrieval systems (in RAG), response caching, etc., which makes LLMs useful for real-world applications like text-to-SQL generators, autonomous sales agents, and customer support chatbots. In contrast, an LLM (Large Language Model) refers specifically to the model (e.g., GPT-4) trained to understand and generate human language.
It’s crucial to remember, though, that an LLM system can occasionally only consist of the LLM itself, as is the case with ChatGPT.
Therefore, evaluating an LLM system is more complicated than evaluating an LLM directly. Even though both LLMs and LLM systems receive and produce textual outputs, you should use LLM evaluation metrics more precisely to assess various LLM system components for a better understanding. This is because an LLM system may have multiple components working together.
Below is the GQM (Goal Question Metric) table that illustrates the key differences in focus.
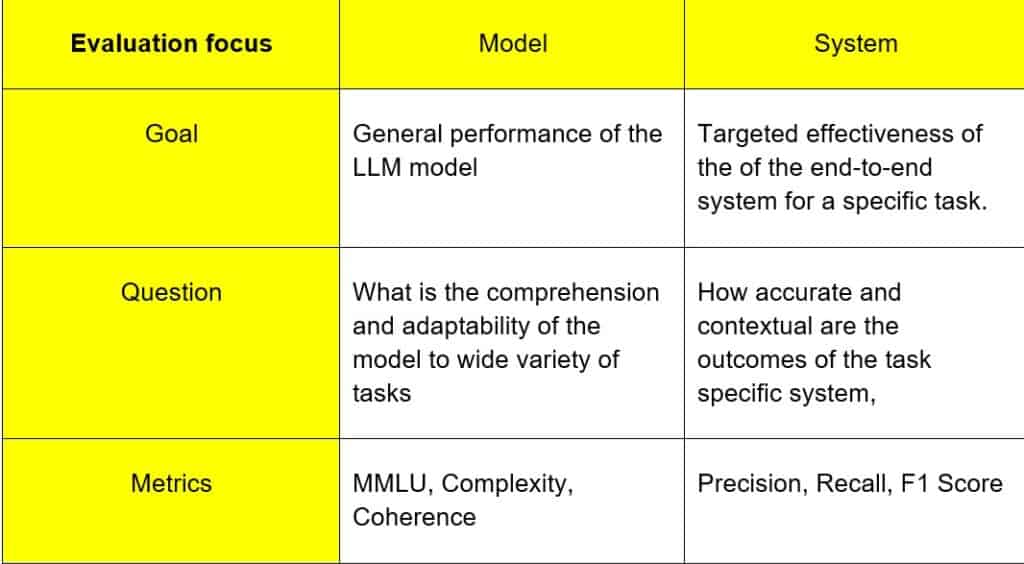
A good evaluation framework must ensure that use case complexity and evaluation architecture approaches are converging. This convergence will give the most relevant metrics.
Reference-based Metrics
A reference, the human-annotated ground truth text, is compared to the generated text using reference-based metrics. Although many of these metrics were created for conventional NLP tasks prior to the development of LLMs, they are still relevant for text produced by LLMs.
N-gram based metrics
The overlap-based measures JS divergence (JS2), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), and BLEU (Bilingual Evaluation Understudy) gauge how similar the reference and output texts are using n-grams.
Text Similarity metrics
By evaluating the overlap of words or word sequences between text parts, evaluators concentrate on calculating similarity. They are helpful in generating a similarity score between reference ground truth text and projected output from an LLM. Additionally, the model’s performance for each task is indicated by these metrics.
Levenshtein Similarity Ratio
A string metric for comparing two sequences’ similarity is the Levenshtein Similarity Ratio. The Levenshtein Distance serves as the basis for this metric. The smallest number of single-character modifications (insertions, deletions, or substitutions) needed to transform one string into another is known as the Levenshtein Distance between two strings.
Semantic Similarity metrics
Sentence Mover Similarity (SMS), MoverScore, and BERTScore metrics all use contextualized embeddings to gauge how similar two texts are. According to studies, these metrics can have poor correlation with human evaluators, lack interpretability, inherent bias, poor adaptability to a wider variety of tasks, and an inability to capture subtle nuances in language, despite being quick, easy, and less expensive to compute than LLM-based metrics.
The degree to which two statements’ meanings are similar is known as their semantic similarity. This is accomplished by first representing each string as a feature vector that encapsulates its semantics and meanings. Making embeddings of the strings (for instance, with an LLM) and then calculating the cosine similarity between the two embedding vectors is a popular method.
Reference-free Metrics
Ground truth is not used by reference-free (context-based) metrics, which instead generate a score for the created text. The context or source document serves as the basis for evaluation. The difficulty of producing ground truth data led to the development of several of these metrics. These approaches are often more recent than reference-based approaches, which reflects the rising need for scale text assessment as PTMs gained power. These include measurements that are based on quality, entailment, factuality, question-answering (QA), and question-generation (QG).
Quality-based Metrics –These metrics are used for summarization tasks, and they are a strong indicator of how relevant the information is in the summary produced.BLANC quality quantifies the discrepancy in accuracy between two reconstructions of masked tokens, while SUPERT quality evaluates how well a summary matches a BERT-based pseudo-reference. ROUGE-C is an adaptation of ROUGE that uses the source text as the context for comparison and does not require references.
Entailment-based: The Natural Language Inference (NLI) task, which assesses whether an output text (hypothesis) implies, contradicts, or undermines a given text (premise), is the foundation of entailment-based metrics [24]. Finding factual inconsistencies can be aided by this. Factual inconsistencies with the source text can be found using the SummaC (Summary Consistency) benchmark, FactCC, and DAE (Dependency Arc Entailment) metrics. The categorization task for entailment-based metrics is labeled “consistent” or “inconsistent.”
Metrics based on QG, QA, and factualness. Metrics based on facts, such as QAFactEval and SRLScore (Semantic Role Labelling), assess whether the generated text contains inaccurate information that deviates from the original text. Factual consistency and relevance are also measured using QA-based metrics, such as QuestEval, and QG-based metrics.
LLM-as Judge
One effective method is LLM-as-a-Judge, which employs LLMs to do LLM (system) reviews by assessing LLM responses according to any particular criterion of your choosing. Giving an LLM an evaluation criterion and letting it grade it for you is a simple idea. The three categories of LLM as judges, which were first presented in the Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena article as a substitute for human evaluation—which is frequently costly and time-consuming—include:
Single Output Scoring (without reference): An LLM judge is given a scoring rubric to use as the criteria and is asked to rate LLM responses according to a number of criteria, including retrieval context in RAG pipelines, input to the LLM system, etc.
Single Output Scoring (with reference): The same as previously, although occasionally LLM judges may become erratic. It is easier for the judge LLM to provide consistent ratings when there is a reference, ideal, and expected output.
Pairwise Comparison: The judge LLM will choose which of the two outputs produced by the LLM is superior in terms of the input. Additionally, a unique set of standards is needed to decide what is “better.”
The use of LLMs as a scorer for LLM evaluation measures to assess other LLMs is becoming more and more popular as the alternatives are insufficient. Although human review is slow and conventional evaluation techniques like BERT and ROUGE fall short by ignoring the underlying semantics in LLM-generated text, LLM evaluation is essential for measuring and pinpointing areas to enhance LLM system performance.
G-Eval
G-Eval is an approach/framework that employs CoT prompts to stabilize and improve the accuracy and dependability of LLM judges when it comes to calculating metric scores.
G-Eval employs a form-filling paradigm to establish the final score after first creating a set of assessment stages based on the original evaluation criteria. This is simply a fancy way of saying that G-Eval needs a number of pieces of information to function. For instance, assessing LLM output coherence with G-Eval entails creating a prompt with the evaluation criteria and text to create evaluation stages and then using an LLM to produce a score ranging from 1 to 5 based on these steps.
Use case Complexity
Various applications demand unique performance metrics that correspond with their particular objectives and specifications. Assessment metrics like BLEU and METEOR are frequently used in the field of machine translation, where producing correct and coherent translations is the key goal. The purpose of these measures is to assess how closely machine-generated translations and human reference translations resemble one another. In this case, it becomes crucial to modify the evaluation criteria to emphasize linguistic accuracy. Metrics like precision, recall, and F1 score may be given priority in applications like sentiment analysis. A metric framework that takes into account the subtleties of sentiment classification is necessary to evaluate a language model’s accuracy in identifying positive or negative feelings in text data. A more pertinent and significant review is guaranteed when evaluation criteria are crafted to highlight certain measures.
RAG architectural Pattern
The Retrieval-Augmented Generation (RAG) pattern is a widely used technique to enhance LLM performance. The process entails obtaining pertinent data from a knowledge base and then producing the end result utilizing a generation model. LLMs can be used for both the creation and retrieval models. The retrieval and generation models’ performance can be assessed using the following metrics from the RAGAS implementation (RAGAS is an evaluation framework for your Retrieval Augmented Generation pipelines; see below), which requires the retrieved context per query:
Generation Related
Faithfulness: Evaluates the generated answer’s factual coherence with the provided context. The answer will be penalized if it contains any statements that cannot be inferred from the context. This is accomplished by employing a two-step paradigm that involves generating statements from the generated response and then confirming each of these statements using inferencing or context. It is calculated from the answer and retrieved context. The response is scaled from 0 to 1, with 1 representing the best result.
Relevancy: The degree to which a response directly responds to and is suitable for a particular question or situation is known as answer relevance. This penalizes the existence of superfluous information or partial replies to a query rather than taking the answer’s factual accuracy into account.
Retrieval Related
Context Relevancy: Indicates how pertinent the contexts that were retrieved are to the query. The context should ideally just provide the details required to respond to the query. It is penalized when redundant information appears in the context. It is computed using the context that was retrieved and the inquiry.
Context Recall: Uses the annotated response as the ground truth to gauge how well the context was remembered. The context of the ground truth is represented by an annotated response. It is computed using recovered context and ground truth.
Ethics and Safety
LLMs will eventually be used on a regular basis by a variety of companies and organizations across the globe. For these models to function at their peak and even adhere to cultural norms, it is imperative that they adhere to ethical and safety assessments.
Identifying Bias
Examine LLM outcomes carefully for instances of unequal treatment or representation of various groups. The metric determines and evaluates the degree to which the model ignores any age, ethnicity, gender, religion, and other stereotypes.
Assessment of Toxicity
This measure assesses the overall likelihood of any offensive, improper, or harmful content. It even makes use of certain algorithms to categorize and rank output based on how likely it is to promote hate speech, foul language, or other similar types of content.
Checks for Factual Correctness
It assesses the general veracity of the data produced by LLM chatbots. To be completely sure that the information provided is trustworthy, it compares the outputs with credible sources or facts, particularly in cases when inaccurate or misleading information could have serious consequences.
Evaluation of Security and Privacy
This measure assesses and guarantees that no private information is inadvertently revealed by the LLM model. Additionally, it provides security against leaks, closely checks the model’s handling of private data, and complies with the most recent privacy laws in the area.



