

Disasters happen, making sudden downtime reality. But there are things all cloud customers can do to survive virtually any outage.
Stuff happens. Failures—both large and small—are inevitable. What is not inevitable is extended periods of downtime.
Consider the day the South Central US Region of Microsoft’s Azure cloud experienced a catastrophic failure. A severe thunderstorm led to a cascading series of problems that eventually knocked out an entire data center. In what some have called “The Day the Azure Cloud Fell from the Sky,” most customers were offline, not just for a few seconds or minutes, but for a full day. Some were offline for over two days. While Microsoft has since addressed the many issues that led to the outage, the incident will long be remembered by IT professionals.
That’s the bad news. The good news is: There are things all Azure customers can do to survive virtually any outage—from a single server failing to an entire data center going offline. In fact, Azure customers who implement robust high-availability and/or disaster recovery provisions, complete with real-time data replication and rapid, automatic failover, can expect to experience no data loss, and little or no downtime whenever catastrophe strikes.
See also: Nutanix sees enterprise cloud winning the cloud race
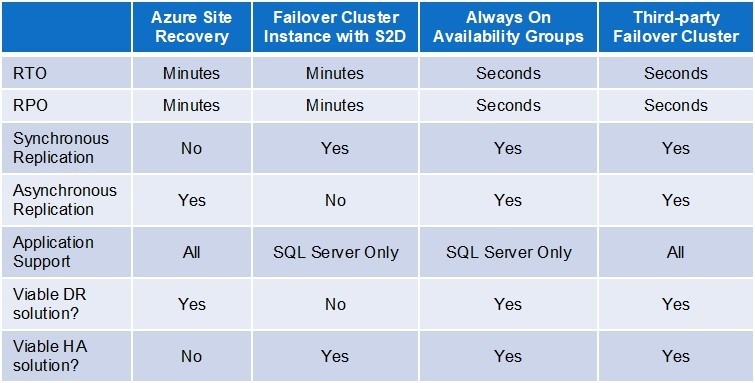
This article examines four options for providing disaster recovery (DR) and high availability (HA) protections in hybrid and purely Azure cloud configurations. Two of the options are specific to the Microsoft SQL Server database, which is a popular application in the Azure cloud; the other two options are application-agnostic. The four options, which can also be used in various combinations, are compared in the table and include:
- The Azure Site Recovery (ASR) Service
- SQL Server Failover Cluster Instances with Storage Spaces Direct
- SQL Server Always On Availability Groups
- Third-party Failover Clustering Software
 RTO and RPO 101
RTO and RPO 101
Before describing the four options, it is necessary to have a basic understanding of the two metrics used to assess the effectiveness of DR and HA provisions: Recovery Time Objective and Recovery Point Objective. Those familiar with RTO and RPO can skip this section.
RTO is the maximum tolerable duration of an outage. Online transaction processing applications generally have the lowest RTOs, and those that are mission-critical often have an RTO of only a few seconds. RPO is the maximum period during which data loss can be tolerated. If no data loss is tolerable, then the RPO is zero.
The RTO will normally determine the type of HA and/or DR protection needed: Low recovery times usually demand robust HA provisions that protect against routine system and software failures, while longer RTOs can be satisfied with basic DR provisions designed to protect against more widespread, but far less frequent disasters.
The data replication used with HA and DR provisions can create the need for a potential tradeoff between RTO and RPO. In a low-latency LAN environment, where replication can be synchronous, the primary and secondary datasets can be updated concurrently. This enables full recoveries to occur automatically and in real-time, making it possible to satisfy the most demanding recovery time and recovery point objectives (a few seconds and zero, respectively) with no tradeoff necessary.
Across the WAN, by contrast, forcing the primary to wait for the secondary to confirm the completion of updates for every transaction would adversely impact on performance. For this reason, data replication in the WAN is usually asynchronous. This can create a tradeoff between accommodating RTO and RPO that normally results in an increase in recovery times. Here’s why: To satisfy an RPO of zero, manual processes are needed to ensure all data (e.g. from a transaction log) has been fully replicated on the secondary before the failover can occur This extra effort lengthens the recovery time, which is why such configurations are often used for DR and not HA.
Azure Site Recovery (ASR) Service
ASR is Azure’s DR-as-a-service (DRaaS) offering. ASR replicates both physical and virtual machines to other Azure sites, potentially in other regions, or from on-premises instances to the Azure cloud. The service delivers a reasonably rapid recovery from system and site outages, and also facilitates planned maintenance by eliminating downtime during rolling software upgrades.
Like all DRaaS offerings, ASR has some limitations, the most serious being the inability to automatically detect and failover from many failures that cause application-level downtime. Of course, this is why the service is characterized as being for DR and not for HA.
With ASR, recovery times are typically 3-4 minutes depending, of course, on how quickly administrators are able to manually detect and respond to a problem. As described above, the need for asynchronous data replication across the WAN can further increase recovery times for applications with an RPO of zero.
SQL Server Failover Cluster Instance with Storage Spaces Direct
SQL Server offers two of its own HA/DR options: Failover Cluster Instances (discussed here) and Always On Availability Groups (discussed next).
FCIs afford two advantages: The feature is available in the less expensive Standard Edition of SQL Server, and it does not depend on having shared storage like traditional HA clusters do. This latter advantage is important because shared storage is simply not available in the cloud—from Microsoft or any other cloud service provider.
A popular choice for storage in the Azure cloud is Storage Spaces Direct (S2D), which supports a wide range of applications, and its support for SQL Server protects the entire instance and not just the database. A major disadvantage of S2D is that the servers must reside within a single data center, making this option suitable for some HA needs but not for DR. For multi-site HA and DR protections, the requisite data replication will need to be provided by either log shipping or a third-party failover clustering solution.
SQL Server Always On Availability Groups
While Always On Availability Groups is SQL Server’s most capable offering for both HA and DR, it requires licensing the more expensive Enterprise Edition. This option is able to deliver a recovery time of 5-10 seconds and a recovery point of seconds or less. It also offers readable secondaries for querying the databases (with appropriate licensing), and places no restrictions on the size of the database or the number of secondary instances.
An Always On Availability Groups configuration that provides both HA and DR protections consists of a three-node arrangement with two nodes in a single Availability Set or Zone, and the third in a separate Azure Region. One notable limitation is that only the database is replicated and not the entire SQL instance, which must be protected by some other means.
In addition to being cost-prohibitive for some database applications, this approach has another disadvantage. Being application-specific requires IT departments to implement other HA and DR provisions for all other applications. The use of multiple HA/DR solutions can substantially increase complexity and costs (for licensing, training, implementation and ongoing operations), making this another reason why organizations increasingly prefer using application-agnostic third-party solutions.
Third-party Failover Clustering Software
With its application-agnostic and platform-agnostic design, failover clustering software is able to provide a complete HA and DR solution for virtually all applications in private, public and hybrid cloud environments, including for both Windows and Linux.
Being application-agnostic eliminates the need for having different HA/DR provisions for different applications. Being platform-agnostic makes it possible to leverage various capabilities and services in the Azure cloud, including Fault Domains, Availability Sets and Zones, Region Pairs, and Azure Site Recovery.
As complete solutions, the software includes, at a minimum, real-time data replication, continuous monitoring capable of detecting failures at the application level, and configurable policies for failover and failback. Most solutions also offer a variety of value-added capabilities that enable failover clusters to deliver recovery times below 20 seconds with minimal or no data loss to satisfy virtually all HA/DR needs.
Making It Real
All four options, whether operating separately or in concert, can have roles to play in making the continuum of DR and HA protections more effective and affordable for the full spectrum of enterprise applications—from those that can tolerate some data loss and extended periods of downtime, to those that require real-time recovery to achieve five-9’s of uptime with minimal or no data loss.
To survive the next outage in the real-world, make certain that whatever DR and/or HA provisions you choose are configured with at least two nodes spread across two sites. Also be sure to understand how well the provisions satisfy each application’s recovery time and recovery point objectives, as well as any limitations that might exist, including the need for manual processes required to detect all possible failures, and trigger failovers in ways that ensure both application continuity and data integrity.



