











Plant managers considering the addition of soft sensors might initially be intimidated by the scope of machine learning. However, a closer look reveals that a few key algorithms form the basis for most soft sensor designs. Although choosing, training, and implementing these algorithms is typically the work of data scientists, it’s useful for plant managers and their teams to have a basic understanding of these algorithms to ensure smooth collaboration.
It’s easy to mistakenly believe that there is one perfect model that will fit every need in machine learning. The truth is that picking one model over another can be intricate and often relies on the data scientist’s expertise. Moreover, these models, especially those designed for supervised regression, won’t always give the same results. This means that there isn’t one “best” model for every situation; instead, some models may be better suited for certain tasks. Successful teamwork in machine learning projects starts with everyone having a clear understanding of the goals, the uses, and the process for creating and using the models.
Soft Sensor Development
Computers have been an integral part of technological advancements for more than a century, but it’s only in the last few decades that soft sensors have gained prominence. These sensors are not physical devices but software-based tools that can emulate the functions of traditional hardware sensors. In certain scenarios, soft sensors are even favored because of their distinct advantages.
Collaboration between operational experts and data scientists is often driven by the need for immediate or almost immediate measurements of critical parameters, which are crucial for achieving desired outcomes and enhancing performance.
Soft sensors find their utility in various situations, such as:
- Staffing Shortage: When laboratory staff are scarce, soft sensors step in to assess certain properties such as viscosity, molecular weight, and composition that would typically require manual sampling and analysis.
- Redundancy: In environments where regular sensors are prone to fouling, soft sensors act as a reliable backup. They provide necessary data to maintain continuous operations until hardware sensors are serviced or replaced.
- Additions: In cases where extra monitoring is needed, or certain processes do not have dedicated sensors, soft sensors can simulate the presence of actual sensors. This ensures all necessary data is captured.
See also: 5 Ways IoT Sensors Are Transforming Outcomes
The Models
Machine learning processes tend to be iterative. They begin with the preparation and cleaning of data. Data scientists then choose an appropriate algorithm to serve as the foundation for the upcoming model. With the algorithm selected, the next step involves training the model with pre-processed or processed contextual and time-series data. Upon completion of the training phase, the model undergoes testing before being put into action. However, this is not the end of the road; the cycle repeats with continual refinements to enhance the model’s performance.
When it comes to model types, there are two primary categories. The first is the supervised model, which relies on a dataset with predefined labels to establish comparisons among variables. The second type, the unsupervised model, is more about delineating the relationships between multiple variables without predefined labels. To create soft sensors or formulate predictive tags, supervised models are generally the more suitable option.
Despite the existence of numerous supervised machine learning models, only a select few, specifically those categorized as regression algorithms, are particularly effective for developing soft sensors.
1. Linear Regression
Linear regression serves as one of the simplest yet most effective methods for developing soft sensors, particularly when the process dynamics are straightforward. This model predicts the value of a target variable ) based on the linear combination of one or more input variables
).
When the model is based on a single variable, it’s termed univariate linear regression. As more variables are incorporated, it becomes multivariate linear regression.
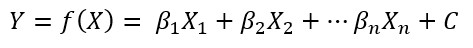
The model coefficients, denoted within the equation, are determined using the Least Squares Method (LSM). This allows for the estimation of various process parameters.
The strength of linear regression lies in its interpretability. It clearly indicates which variables have a significant impact on the target, a concept known as feature importance. However, it’s worth noting that linear regression may not be suitable for processes that involve more complex, non-linear interactions, such as measuring the viscosity of certain materials.
2. Decision Tree/Random Forest
Decision trees, as shown in Figure 1, organize data using a system of rules and branches. Each stems from independent variables known as features. They excel in breaking down complex data, yielding a piecewise constant estimate for the target variable. Decision trees are adaptable and capable of forming numerous rules and branches. However, they carry a risk of overfitting—a condition where the model learns the noise in the data, which impairs its ability to generalize to new situations. Underfitting the data also can occur. In that case, the algorithm is not trained long enough to know the target variables or how features influence them.
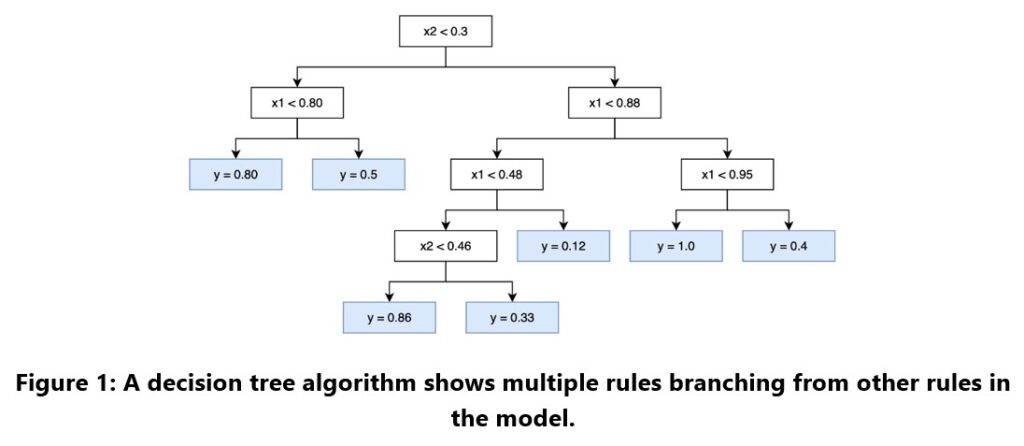
A random forest aggregates several decision trees. This enhances the model’s capacity to include a broad range of features, which improves its predictive strength. Like its constituent trees, a random forest can overfit if not properly calibrated.
3. Support Vector Machines
Support Vector Machines (SVMs) are a class of supervised machine learning algorithms ideal for both classification and regression tasks. Known for their effectiveness in binary classification problems, SVMs can also be extended for multi-class scenarios and regression challenges.
The core concept of SVMs is to identify the best-separating hyperplane that divides the data points of different classes in a high-dimensional space. This hyperplane is selected to maximize the margin, which is the distance between the plane and the nearest points of each class, labeled as support vectors. The objective is to create a model with a margin that is as wide as possible, which ensures robustness and better performance on unseen data. An example of an implementation of an SVM model to predict a discrete measurement is shown in Figure 2.
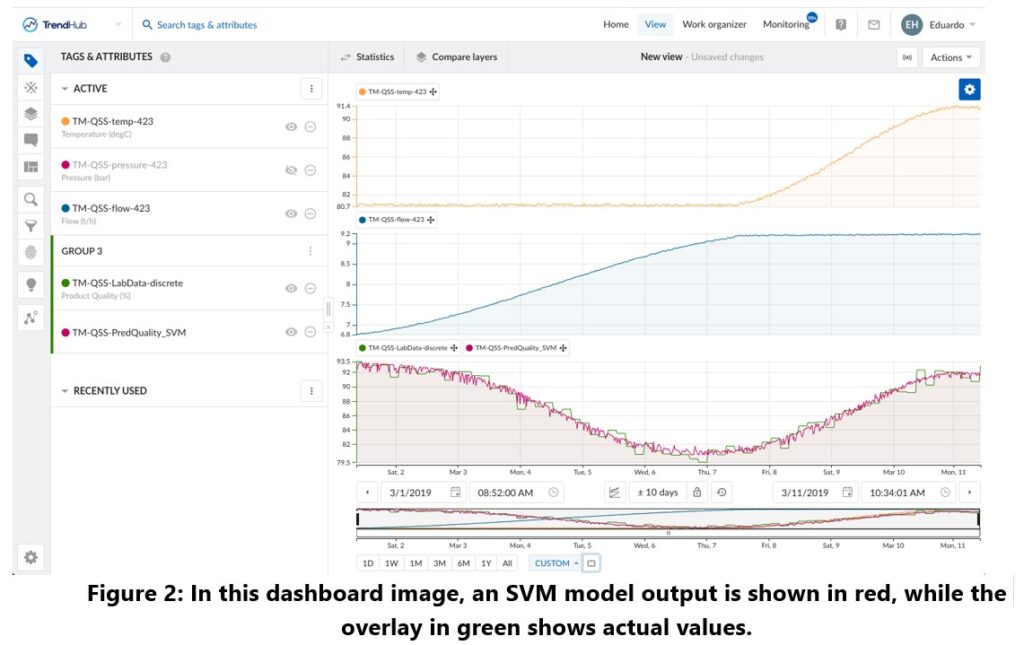
SVMs are particularly adept at handling complex, high-dimensional data sets. They are resistant to overfitting, especially in situations where the number of dimensions exceeds the number of samples.
4. Gradient Boosting
Gradient boosting is a technique in machine learning known for its predictive power. It belongs to a group of models called ensemble models. Like a random forest, gradient boosting creates a prediction model from many decision trees. The difference lies in its approach: gradient boosting refines each tree to correct errors from the previous ones by focusing on minimizing a loss function. These models are highly effective, yet as they grow, their complexity can make them harder to understand.
5. Neural Network
Neural networks, which are the foundation of deep learning, use a structure inspired by the human brain to process data. A basic form of a neural network is the multilayer perceptron (MLP), which uses layers of neurons in a network to make predictions or decisions. While a simple MLP has a single layer, more complex networks include multiple layers known as hidden layers, each contributing to the model’s ability to capture and learn from data patterns, as shown in Figure 3.
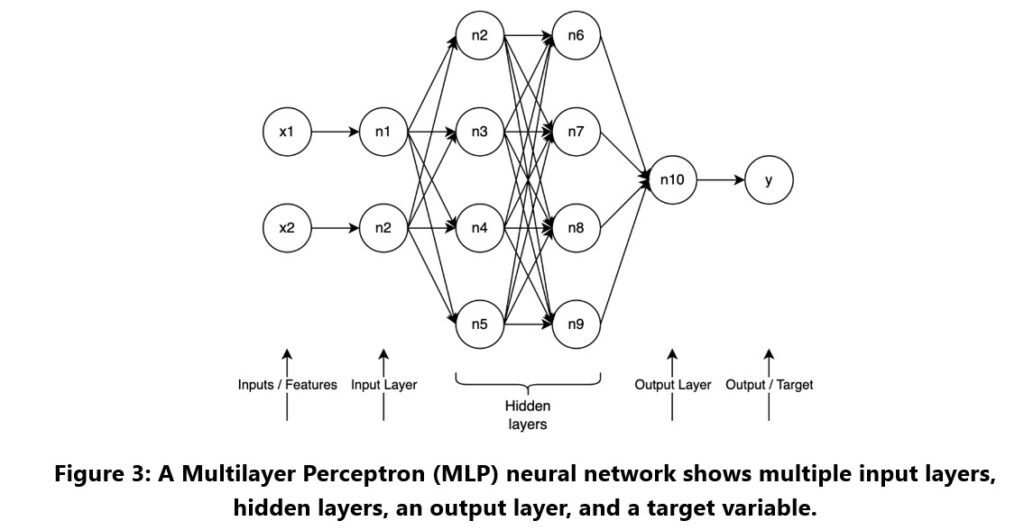
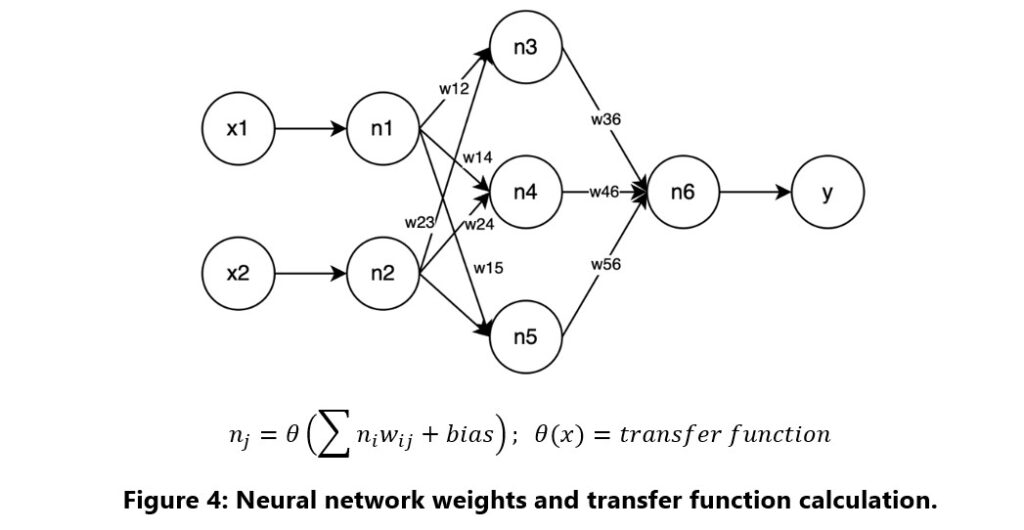
In these networks, each neuron’s value is determined by combining weighted inputs and applying an activation function. This non-linear function allows the model to handle complex relationships within the data. The learning process involves adjusting these weights and biases to align closely with the features and target outcomes, as shown by the diagram and calculation in Figure 4.
Concluding Thoughts
A clear understanding of machine learning models lays the groundwork for effective collaboration between engineers and data scientists. It enables operational experts to engage more meaningfully in the data science process. With a strong grasp of these algorithms, engineers can significantly contribute to the design of soft sensors and ensure that the final models are well-tuned to the operational requirements and challenges they are meant to address.







