

Federated Averaging represents a significant advancement in the use of artificial intelligence in privacy-sensitive applications. By allowing for collaborative model training without direct data sharing, it paves the way for a new era of secure, decentralized machine learning.
In the rapidly evolving field of data privacy and decentralized computing, Federated Learning (FL) stands out by enabling collaborative machine learning without compromising the privacy of individual data sources. Central to this paradigm is Federated Averaging (FedAvg), an algorithm that optimizes data analysis across multiple decentralized endpoints. This article explores the core principles of Federated Averaging, examining its operational mechanics, benefits, and the obstacles it addresses.
How Federated Averaging Works
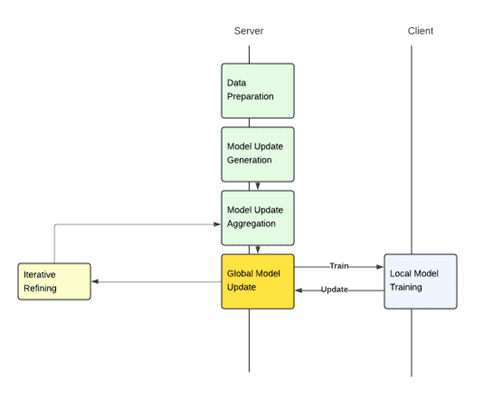
Local Model Training: In a typical Federated Learning scenario, multiple client devices, each with its unique dataset, train local machine learning models. This decentralization ensures that personal or sensitive data remains strictly on the device, never shared or exposed to external threats.
Aggregation: Once local training phases are complete, each device computes model updates—essentially, changes made to model parameters during training. These updates are sent to a central server where Federated Averaging comes into play.
Model Update: The central server uses FedAvg to combine these updates into a new, improved global model. This model synthesizes learning from all participating devices. It is then sent back to the devices, updating their local models and starting the next iteration of training.
Advantages of Federated Averaging
Privacy Preservation: By only exchanging updates to model parameters rather than raw data, Federated Averaging keeps sensitive information securely on the device.
Efficient Communication: Since only parameter updates are transmitted, rather than entire datasets, the method significantly reduces the bandwidth required for communication, making it feasible even for devices with limited connectivity.
Improved Model Accuracy: Aggregating diverse updates from a wide range of devices and data distributions enhances the robustness and generalizability of the global model, often resulting in higher accuracy than any single device could achieve alone.
Understanding the Loss Landscape
To grasp why Federated Averaging is effective, particularly in heterogeneous environments, it’s helpful to consider the “loss landscape”—an abstract representation of how different parameter settings of a model affect its performance (loss).
Visualizing Loss Landscape: By mapping out this landscape, researchers can visualize where the global model falls relative to the ideal lowest-loss point (the global minimum). Surprisingly, even when the global model does not hit the absolute lowest point, it often achieves better performance than models trained on individual datasets.
See also: Real-Time Data Fueling Artificial Intelligence ‘Factories’
Addressing Deviation with Iterative Moving Averaging (IMA)
Problem of Deviation: One notable challenge in Federated Learning is that the global model may stray from the optimal path in the loss landscape due to the varied nature of data across devices. This deviation can degrade the model’s effectiveness.
Solution with IMA: Iterative Moving Averaging addresses this by periodically adjusting the global model using a moving average of previous models. This technique not only corrects deviations but also smoothens the model’s trajectory through the loss landscape, leading to more stable and accurate learning outcomes.
Overcoming Challenges in Federated Averaging
Device Heterogeneity: Disparities in device capabilities and data types can skew the learning process. Transfer learning and adaptive techniques like data normalization help align disparate data types and distributions, ensuring coherent and effective aggregation.
Communication Overhead: Regular transmission of updates can be communication intensive. Techniques such as data compression and protocol optimization are employed to manage this load efficiently, ensuring the system’s scalability.
Security Threats: The decentralized nature of Federated Learning can introduce vulnerabilities, such as data poisoning or model tampering. Advanced cryptographic techniques, like secure multi-party computation and differential privacy, are integrated to safeguard the system against such threats.
Federated Averaging in Action
Healthcare and Finance Applications: In sectors like healthcare and finance, where data sensitivity is paramount, Federated Averaging enables predictive analytics and fraud detection without compromising individual data privacy. Real-world examples include hospitals predicting patient outcomes and banks detecting fraudulent activities, all while maintaining strict data confidentiality.
Conclusion
Federated Averaging represents a significant advancement in the use of artificial intelligence in privacy-sensitive applications. By allowing for collaborative model training without direct data sharing, it paves the way for a new era of secure, decentralized machine learning. As technology evolves and more industries adopt Federated Learning, the impact of Federated Averaging will continue to grow, reinforcing its role as a cornerstone of modern AI strategies.
References
- Zhou, T., Lin, Z., Zhang, J., & Tsang, D. H. K. (2023, May 13). Understanding and improving model averaging in federated learning on heterogeneous data. arXiv.org. https://arxiv.org/abs/2305.07845
- Cross-silo and cross-device federated learning on Google Cloud. (2024, April 12). Google Cloud. https://cloud.google.com/architecture/cross-silo-cross-device-federated-learning-google-cloud
- Federated Learning of Cohorts (FLOC) – the privacy sandbox. (n.d.). https://privacysandbox.com/proposals/floc/
- Scatter and Gather Workflow — NVIDIA FLARE 2.1.2 documentation. (n.d.). https://nvflare.readthedocs.io/en/2.1/programming_guide/controllers/scatter_and_gather_workflow.html#scatter-and-gather-workflow




