


Open Data Hub is an open-source community project that implements end-to-end workflows for AI and ML with containers on Kubernetes on OpenShift.
Businesses are increasingly turning to intelligent applications to increase operational efficiencies and be more responsive to customers. A critical element of this move is the more pervasive use of artificial intelligence (AI) and machine learning (ML) on vast amounts of data to derive the necessary insights needed to determine the next steps in a process, make decisions, and take actions.
However, most businesses face challenges when undertaking such efforts. Problems arise because multiple groups, including data engineers, data scientists, DevOps, and the business units, must be involved. These diverse groups have typically worked independently. Each group performs its needed work as they see fit and then hands off the product of that work to the next group in line. Little consideration is given to how the groups could gain synergistic advantages by working together.
The siloed approach, where each group works on their own, must be addressed as automation becomes more widely used and essential for business success. The specific point that must be addressed is that modern applications deal with much larger data volumes from different sources. The data can be structured and unstructured, real-time, and streaming. The result is increasingly complex data pipelines.
What’s needed to enable cooperation and collaboration between the various stakeholders is a common platform that helps each group, allowing them to use the tools of choice for the different functions they must perform and support.
Architectural aspects of modern application workflows
A look at the elements of AI application workflows helps put the challenges businesses encounter into perspective.
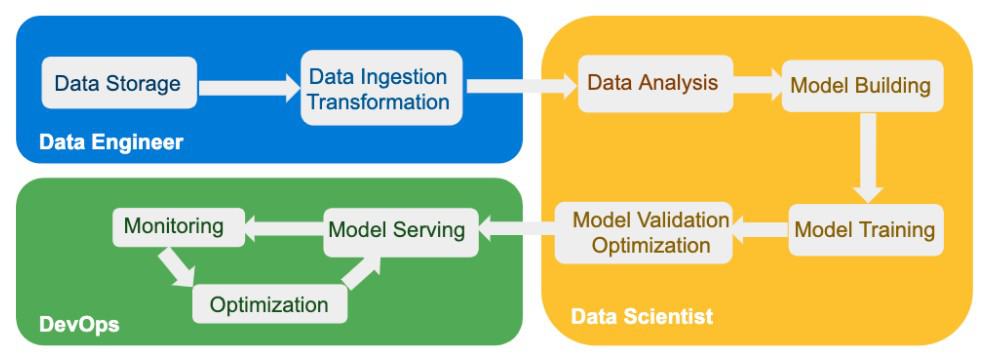
A traditional workflow consists of several distinct stages. Each stage uses different tools and requires different skill sets. The stages include:
Data storage and ingestion: Data engineers typically carry out this stage. It involves managing data capture and storage, using tools to make that data accessible to applications, and transforming the data so that it is in the format required by the applications. While data storage and ingestion have long been routine operations, challenges now emerge due to the large volume of data used in businesses today and the diversity in data types.
Data analysis, model building, model training, and model optimization: Data scientists lead the work in this stage. They select suitable analysis methodologies and decide which AI/ML models to use, create, train those models, and verify that the models work as intended. Work conducted in this stage is dependent on easy access to data and the availability of resources (skilled data scientists and compute capacity) to build and test the AI/ML models. A growing challenge for this group is to develop models and methodologies that are reproducible and transparent so that results can be explained and justified.
Model deployment, monitoring, and optimization: Once models are tested and optimized by the data scientists, they are handed off to DevOps engineers, who are responsible for deploying the services. DevOps makes decisions about which platform and where (on-premises, private cloud, or public cloud) to run the models and applications. They monitor and optimize the services to ensure that users of the applications have the responsiveness needed to conduct business and complete their work.
The groups managing these elements use a wide variety of solutions but need a common architectural platform. Such a platform is typically cloud-native-based, using containers to run distributed workloads. Containers can use Kubernetes, an open-source platform, to automate the deployment and management of containerized applications. Specifically, Kubernetes provides service discovery and load balancing, storage orchestration, self-healing, automated rollouts and rollbacks, and more.
Why adopt this architecture? Developing, deploying, and maintaining AI/ML-based applications requires a lot of ongoing work. Containers offer a way for processes and applications to be bundled and run. They are portable and easy to scale. They can be used throughout an application’s lifecycle from development to test to production. And they also allow large applications to be broken into smaller components and presented to other applications as microservices.
Many organizations use Red Hat OpenShift as this container platform because it offers the essential enterprise-class features and support for production applications.
The role of Open Data Hub (ODH)
The vast array of tools and solutions used by the different groups can use Red Hat OpenShift. But there still needs to be a type of glue that lets the groups more easily collaborate. Developing and deploying an intelligent application is not a one-and-done process. New data must be accommodated as it becomes available, models must be retrained based on new data and new conditions, and DevOps must share feedback from users to institute improvements and address problems.
One way to accomplish this is with an architecture that builds in needed technologies for an end-to-end workflow, taking into account the lifecycle issues. Enter Open Data Hub (ODH). ODH complements the capabilities of OpenShift. It is a centralized self-service blueprint for analytic and data science distributed workloads. It offers a collection of open-source tools and services that natively run on OpenShift and Red Hat products (e.g., Red Hat Ceph Storage and AMQ Streams, aka Kafka).
Additionally, ODH is a reference implementation on how to build an open AI/ML-as-a-service solution based on OpenShift with open-source tools such as Tensorflow, JupyterHub, Spark, and others. OpenShift also integrates with key AI/ML software and hardware from NVIDIA, Seldon, Starbust, and others to help operationalize an AI/ML architecture.
An example of ODH in action can be found in work being done at Mass Open Cloud.
The Mass Open Cloud (MOC) is a production public cloud being developed based on an Open Cloud Exchange (OCX). In this model, many stakeholders, rather than just a single provider, participate in implementing and operating the cloud. Hosted at Boston University and housed at the Hariri Institute for Computing, the project is a collaborative effort between higher education, government, non-profit entities, and industry. The Mass Open Cloud goal is to create an inexpensive and efficient at-scale production cloud utility suitable for sharing and analyzing massive data sets and supporting a broad set of applications. The effort helps different organizations meet the challenges of deploying AI in production and using it to improve business outcomes.
A final note
Open Data Hub is an open-source community project that implements end-to-end workflows from data ingestion to transformation to model training and serving for AI and ML with containers on Kubernetes on OpenShift.
Learn more about the benefits of using OpenShift for AI and ML: https://www.redhat.com/en/resources/openshift-for-ai-ml-e-book




